


글로벌 연구동향
의학물리학

![[Med Phys.] A performance comparison of convolutional neural network-based image denoising methods: The effect of loss functions on low-dose CT images.](/enewspaper/upimages/1572503767admin.JPG) [Med Phys.] A performance comparison of convolutional neural network-based image denoising methods: The effect of loss functions on low-dose CT images.AI 컨볼루션 신경망을 이용한 영상 잡음 제거 성능 비교 연구
[Med Phys.] A performance comparison of convolutional neural network-based image denoising methods: The effect of loss functions on low-dose CT images.AI 컨볼루션 신경망을 이용한 영상 잡음 제거 성능 비교 연구연세대 / 김병준, 한민아, 심현정*, 백종덕*
- 출처
- Med Phys.
- 등재일
- 2019 Sep
- 저널이슈번호
- 46(9):3906-3923. doi: 10.1002/mp.13713. Epub 2019 Aug 6.
- 내용
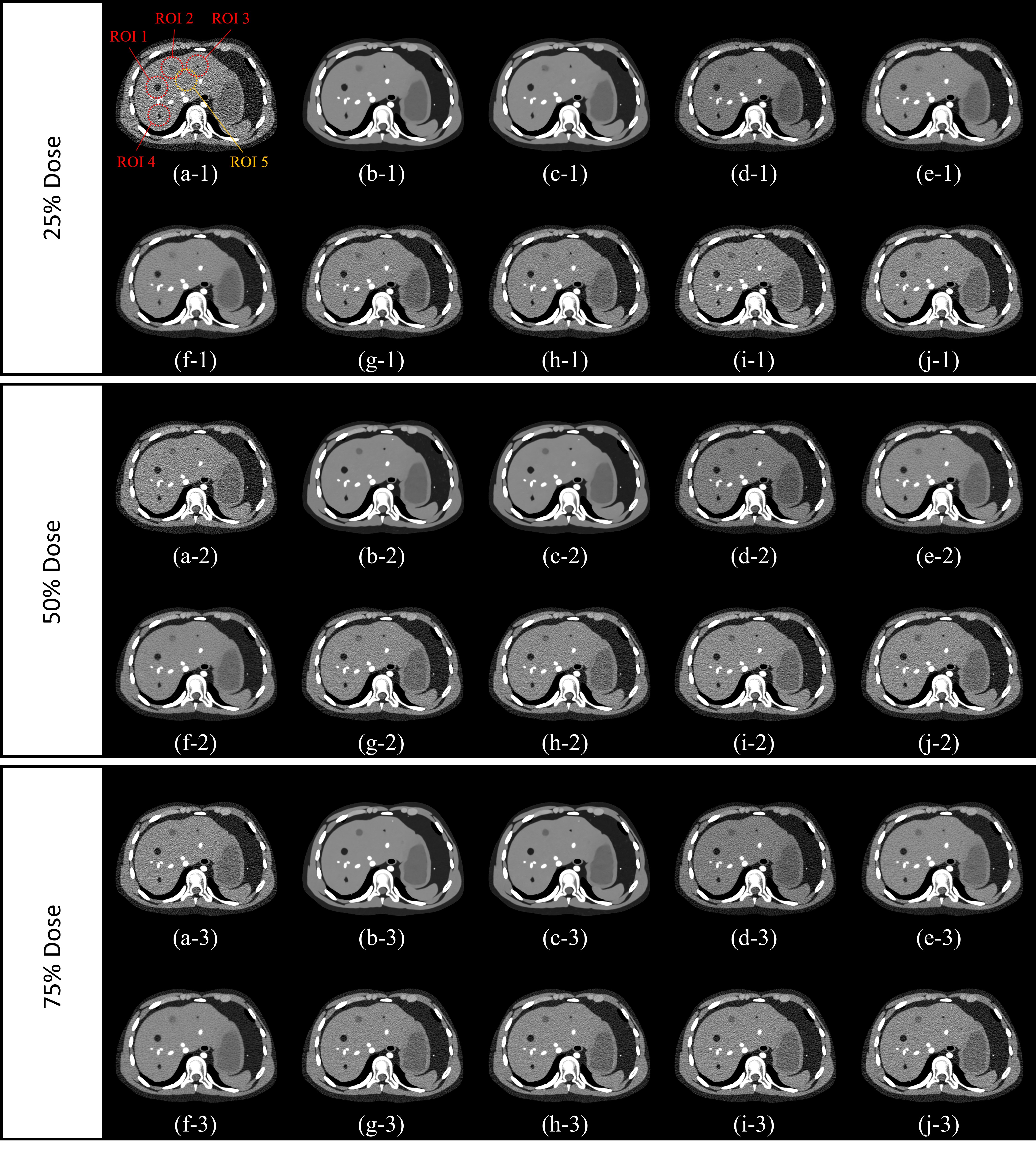
합성곱 신경망을 학습하는 데에 사용하는 손실함수로 대표적으로 평균제곱오차(mean squared error ;MSE)와 평균절대오차(mean absolute error; MAE), 지각손실(perceptual loss), 그리고 적대손실(adversarial loss) 등이 있습니다. 본 연구에서는 이들 각각 또는 이들의 조합을 손실함수로 사용하여 저선량 CT영상의 노이즈를 제거하기 위한 합성곱 신경망을 학습시켰습니다. 데이터는 XCAT 시뮬레이션 및 Mayo Clinic에서 제공받은 실측 데이터를 사용하였습니다. 기본 선량의 25%, 50%, 75%영상으로 촬영된 저선량 CT영상에 대하여 노이즈 제거를 진행하였고, 잡음력 스펙트럼과 변조 전달 함수, 그리고 수학적 관찰자를 통한 병변 검출능을 측정하였습니다. 그 결과, 선량의 세기나 병변의 종류에 따라 다르긴 하지만 많은 경우 지각손실함수와 적대손실 함수를 함께 사용하는 경우 기존의 반복적 재구성 방법에 비해 노이즈를 효과적으로 제거하면서도 해상도를 잘 유지한다는 것을 보였습니다.
Abstract
PURPOSE:
Convolutional neural network (CNN)-based image denoising techniques have shown promising results in low-dose CT denoising. However, CNN often introduces blurring in denoised images when trained with a widely used pixel-level loss function. Perceptual loss and adversarial loss have been proposed recently to further improve the image denoising performance. In this paper, we investigate the effect of different loss functions on image denoising performance using task-based image quality assessment methods for various signals and dose levels.METHODS:
We used a modified version of U-net that was effective at reducing the correlated noise in CT images. The loss functions used for comparison were two pixel-level losses (i.e., the mean-squared error and the mean absolute error), Visual Geometry Group network-based perceptual loss (VGG loss), adversarial loss used to train the Wasserstein generative adversarial network with gradient penalty (WGAN-GP), and their weighted summation. Each image denoising method was applied to reconstructed images and sinogram images independently and validated using the extended cardiac-torso (XCAT) simulation and Mayo Clinic datasets. In the XCAT simulation, we generated fan-beam CT datasets with four different dose levels (25%, 50%, 75%, and 100% of a normal-dose level) using 10 XCAT phantoms and inserted signals in a test set. The signals had two different shapes (spherical and spiculated), sizes (4 and 12 mm), and contrast levels (60 and 160 HU). To evaluate signal detectability, we used a detection task SNR (tSNR) calculated from a non-prewhitening model observer with an eye filter. We also measured the noise power spectrum (NPS) and modulation transfer function (MTF) to compare the noise and signal transfer properties.RESULTS:
Compared to CNNs without VGG loss, VGG-loss-based CNNs achieved a more similar tSNR to that of the normal-dose CT for all signals at different dose levels except for a small signal at the 25% dose level. For a low-contrast signal at 25% or 50% dose, adding other losses to the VGG loss showed more improved performance than only using VGG loss. The NPS shapes from VGG-loss-based CNN closely matched that of normal-dose CT images while CNN without VGG loss overly reduced the mid-high-frequency noise power at all dose levels. MTF also showed VGG-loss-based CNN with better-preserved high resolution for all dose and contrast levels. It is also observed that additional WGAN-GP loss helps improve the noise and signal transfer properties of VGG-loss-based CNN.CONCLUSIONS:
The evaluation results using tSNR, NPS, and MTF indicate that VGG-loss-based CNNs are more effective than those without VGG loss for natural denoising of low-dose images and WGAN-GP loss improves the denoising performance of VGG-loss-based CNNs, which corresponds with the qualitative evaluation.
Author informationKim B1, Han M1, Shim H1, Baek J1.
1
School of Integrated Technology and Yonsei Institute of Convergence Technology, Yonsei University, Incheon, 21983, South Korea.
- 키워드
- adversarial loss; deep learning; feature-level loss; image denoising; low-dose CT; mathematical observer; modulation transfer function; noise power spectrum
- 연구소개
- 저선량 CT는 CT 촬영 시 사용하는 선량을 낮추어 환자가 받게 되는 방사선 피폭선량을 크게 줄이는 기술입니다. 이 기술을 개발함에 있어서 가장 중요한 것은 낮아진 선량으로 인하여 영상에 증폭된 노이즈를 제거하는 일입니다. 이에 합성곱 신경망(convolutional neural network; CNN)을 활용하는 딥러닝 방법이 최근 활발하게 연구되어왔고 기존 기술을 뛰어넘는 긍정적인 결과들을 보여주었습니다. 그러나 여전히 충분한 정량적 지표가 제시되지 않았다는 점에서 그 결과를 신뢰하기 어려운 부분이 있었습니다. 따라서 본 연구에서는 딥러닝 기반 기술의 성능을 영상의 해상도와 노이즈 특성, 그리고 병변 검출능 등 다각적인 측면에서 정량적으로 평가하고 기존 기술과 비교하여 딥러닝 기반 기술의 우수성을 보였습니다. 또한 본 연구에서는 합성곱 신경망의 학습에 사용하는 손실함수의 선택에 따른 성능 변화를 다양한 선량 조건과 병변 종류에 대하여 분석하였습니다. 그 결과, 딥러닝의 비선형적인 특성상 상황마다 적합한 손실함수가 다르다는 것이 보여졌으며, 따라서 앞으로 딥러닝 기반 기술을 연구함에 있어서 적합한 손실함수 설계가 매우 중요할 것으로 생각됩니다.
- 덧글달기



![]()
- COPYRIGHT(C) 2015 한국원자력의학원 전략기획팀 All rights Reserved.
- 문의 : rmwebzine@kirams.re.kr 발행처 : 한국원자력의학원 전략기획팀
- 우) 01812 서울시 노원구 노원로 75 한국원자력의학원 전략기획팀
편집위원
의료영상에 다양한 modality가 있지만 상대적으로 저렴하면서도 많은 정보를 얻을 수 있는 CT영상의 촬영이 더욱 빈번해 지면서 영상선량을 줄이려는 노력과 함께 영상의 질을 높이려는 연구도 다양하게 이루어 지고 있다. 특히 최근 각광을 받고 있는 인공지능을 이용하여 CT영상의 노이즈를 감소시키려는 연구도 활발히 진해되고 있는데 인공지능에 사용된 CNN 모델 뿐만 아니라 사용된 loss function들간의 차이를 tSNR, NPS 등 몇 가지 툴을 사용하여 비교한 논문으로 앞으로 선명한 영상을 얻을 수 있는 저선량CT가 나오길 기대해 본다.
2019-10-30 17:14:20